[BOJ] Python 백준 1806번 부분합 골드 4


https://www.acmicpc.net/problem/1806
1806번: 부분합
첫째 줄에 N (10 ≤ N < 100,000)과 S (0 < S ≤ 100,000,000)가 주어진다. 둘째 줄에는 수열이 주어진다. 수열의 각 원소는 공백으로 구분되어져 있으며, 10,000이하의 자연수이다.
www.acmicpc.net
문제 풀이
자연수로 이루어진 수열이므로 연속된 합을 구하는 다양한 알고리즘 중에 투 포인터(Two Pointer) 알고리즘을 사용하는 문제다.
만약 투 포인터에 대해 잘 모르겠다면 밑에 있는 더보기를 눌러서 설명을 보고 이해하기 바란다.
투 포인터 알고리즘이란 두 개의 지점을 이동시키면서 연속된 숫자의 합(구간 합)을 구하는 알고리즘이다.
비슷한 알고리즘으로 슬라이딩 윈도우(Sliding Window)가 있는데 이 둘의 차이점은 구간의 길이다.
슬라이딩 윈도우는 구간의 길이가 정해져 있고, 투 포인터는 상황에 따라 변한다.
또한 투 포인터는 음수가 존재할 경우 구간의 길이가 증가했을 때 구간 합이 증가할지 감소할지 보장할 수 없으므로 양의 정수만 존재할 때 사용 가능하다는 특징이 있다.
그림을 통해 이해하면 쉬울 것이다.

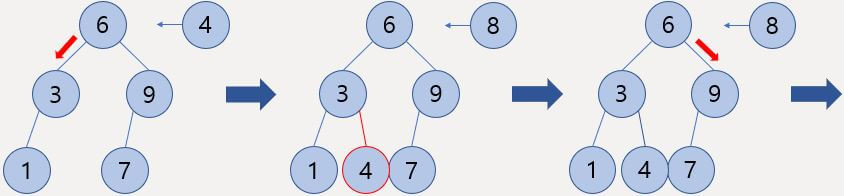
다음과 같이 자연수로 이루어진 리스트가 있을 때 합이 5인 구간의 최소 길이를 찾는 예시를 보자.
이때 두 가지 변수를 Left, Right로 선언하고 처음부터 Right 변수를 오른쪽으로 움직이며 구간 합에 원소를 합하고 Left 변수를 오른쪽으로 움직이며 구간합에 원소를 빼는 방식이다.

먼저 Right 변수가 첫 번째 원소를 가리킬 때다.
Sum에 해당하는 원소를 더하고 5와 비교했을 때 더 작으므로 구간을 늘려야 한다.
따라서 Right 변수를 옮겨야 한다.

Right 변수를 옮기고 나서 구간합이 5가 되므로 이 구간의 길이를 갱신시키면 된다.
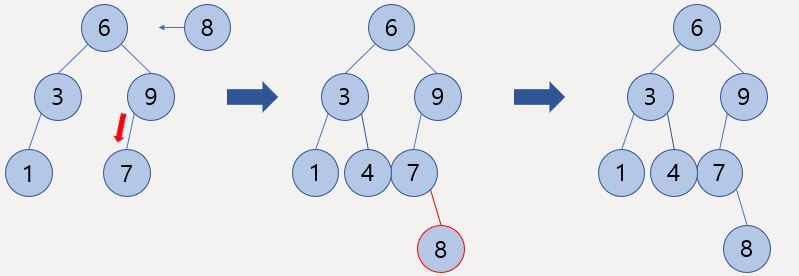
최소 길이를 구해야 하므로 Left 변수를 옮기면 된다.

Left 변수를 옮기고 나서 Sum이 5보다 작으므로 Right 변수를 옮긴다.

Right 변수를 옮긴 뒤 Sum이 5보다 크므로 Left 변수를 옮겨 구간 합을 더 작게 만든다.

Left 변수를 옮기고 Sum이 5보다 더 크지만 동일한 원소(구간의 길이가 1)를 가리키므로 Right 변수를 옮긴다.

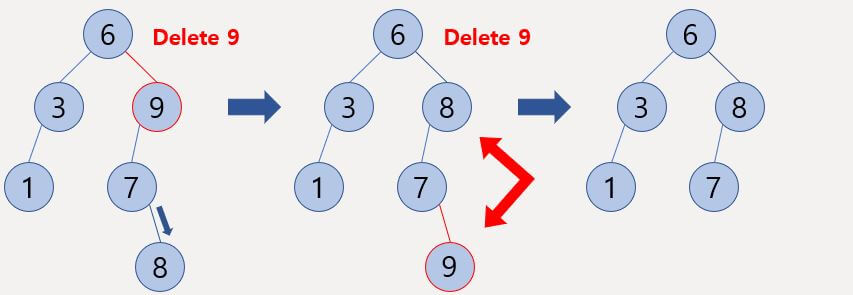
Right 변수를 옮긴 뒤 Sum이 5보다 크므로 Left 변수를 옮긴다.

Left 변수를 옮긴 뒤 해당 원소를 빼주니 Sum이 5이다.
해당 구간의 길이는 1이므로 구간 길이를 갱신해주고 Right 변수를 옮긴다.

Right 변수를 옮기니 리스트를 벗어나므로 탐색을 종료한다.
인덱싱을 어떻게 구현하는지는 본인의 자유이며 인덱싱 과정이 헷갈릴 수 있기에 여러 가지 방법 중에 가장 자신한테 적합한 방식을 적용하는 편이 좋을 것 같다.
다음은 문제를 푼 전체 코드이다.
n,s=map(int,input().split())
left=-1
right=0
min_len=100001
num_array=list(map(int,input().split()))
temp_sum=num_array[0]
while right<n:
if temp_sum>=s:
if min_len>right-left:
min_len=right-left
left+=1
temp_sum-=num_array[left]
else:
right+=1
if right<n:
temp_sum+=num_array[right]
if min_len==100001:
print(0)
else:
print(min_len)
문제에서 수열의 길이 N은 100000 미만이므로 100000 이상의 숫자 중 아무거나 구간의 최소 길이로 정하고 그걸 갱신하면 최소 길이를 구할 수 있다.
만약 처음에 정한 숫자가 그대로 있다면 합이 s보다 큰 구간이 없단 뜻이며 4번째 줄에선 선언하고, 17번째 줄에선 판단하도록 구현했다.
7번째 줄의 while문에서는 right 변수가 수열의 길이를 넘어가면 안 되므로 길이(n) 미만일 때까지만 반복을 한다.
또한 while문 내부에서는 구간합이 S이상이면 길이를 갱신하고 Left를 이동시켜 원소를 구간합에서 빼고 구간합이 S미만이면 Right를 이동시켜 원소를 구간합에 더하도록 구현했다.

인덱싱 과정이 다소 헷갈릴 수 있는 알고리즘이라서 소수의 원소를 집어넣고 접근하는 과정을 하나씩 출력하다 보면 실수를 줄일 수 있을 것이다.
'알고리즘 > 알고리즘 문제 풀이' 카테고리의 다른 글
| [BOJ] Python 백준 10818번 최소, 최대 브론즈 3 (0) | 2021.12.24 |
|---|---|
| [BOJ] Python 백준 11053번 가장 긴 증가 부분 수열 실버 2 (0) | 2021.12.24 |
| [BOJ] Python 백준 1991번 트리 순회 실버 1 (0) | 2021.12.20 |
| [BOJ] Python 백준 1012번 유기농 배추 실버 2 (0) | 2021.12.20 |
| [BOJ] Python 백준 23841번 데칼코마니 브론즈 2 (0) | 2021.12.19 |