[자료구조] 힙(Heap) (Python)


설명
힙(Heap)은 트리(Tree)의 일종으로 우선순위 큐로 활용이 가능하다.
만약 트리에 대해 처음 보거나 익숙하지 않은 상태라면 해당 링크를 통해 이해한 뒤 학습해야 이해가 될 것이다.
https://khsung0.tistory.com/24
[자료구조] 트리(Tree) 이진 트리(Binary Tree) (Python)
설명 자료구조는 크게 선형 구조, 비선형 구조로 나눠진다. 선형 구조는 Data를 차례대로 나열시킨 형태를 뜻하고 비선형 구조는 선형 구조가 아닌 모든 형태를 말한다. 즉, 노드와 간선으로 이루
khsung0.tistory.com
힙은 최대 힙(Max Heap), 최소 힙(Min Heap) 두 가지가 있다.
이진 탐색 트리(Binary Search Tree)를 기반으로 최대 힙은 항상 루트 노드가 가장 큰 원소임을, 최소 힙은 항상 루트 노드가 가장 작은 원소임을 보장하는 자료구조가 힙이다.
여기서 중요한 점은 항상 루트 노드를 보장한다는 점이다.
즉, 루트 노드를 제외한 나머지 노드는 정렬되어 있지 않기 때문에 리스트의 정렬이 필요한 상황이 아닌, 최솟값 혹은 최댓값이 필요한 상황에서 사용 가능하다.
물론 삽입과 삭제가 발생해도 갱신을 통해 항상 루트 노드는 특성을 유지하며 갱신 과정에서 범위를 절반씩 줄이기 때문에 O(logn)의 아주 효율적인 시간 복잡도가 걸린다.
만약 N개의 Data가 있는 리스트에서 최댓값 혹은 최솟값을 매번 찾아야 한다면 O(n)의 시간 복잡도가 걸리는 선형 탐색보다 힙을 사용하는 게 훨씬 효율적이다.
예시는 그림을 통해 최대 힙으로 설명할 것이며 최소 힙도 같은 원리로 작동한다.
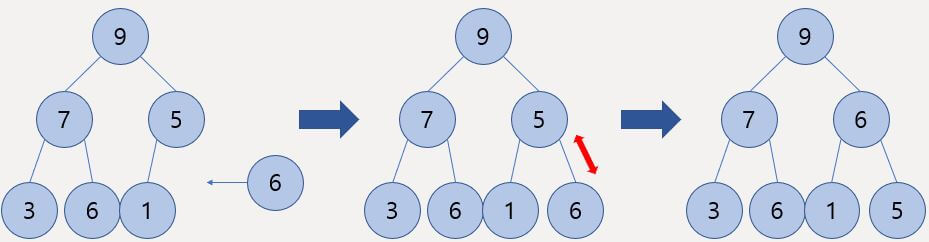
먼저 최대 힙의 삽입 연산이다.
가장 끝 부분에 원소를 넣는다.
그리고 힙의 특성을 유지하기 위한 갱신 과정을 거치는데 이 과정을 Heapify라고 한다.
따라서 최대 힙이기에 삽입된 6과 부모 노드인 5를 비교해봤을 때 부모 노드가 더 작으므로 서로 교환해준다.
그다음 교환한 부모 노드로 가서 다시 해당 노드와 부모 노드를 비교해주는데 여기선 부모 노드가 더 크므로 힙의 특성을 지키고 있기 때문에 갱신 과정은 종료된다.

다음은 최대 힙의 삭제 연산이다.
삭제는 항상 루트 노드를 제거함으로써 최댓값의 반환을 보장하고 마지막 원소를 루트 노드로 가져온다.
여기부터 힙의 특성을 유지하기 위한 Heapify가 진행되는데 자식 노드와 비교해서 자신보다 큰 원소가 있다면 교환을 하고 해당 자식 노드로 넘어간다.
이때 자식 노드가 하나만 있다면 그 하나와 비교를 하고 두 개가 있다면 그중 아무거나 자신보다 큰 원소와 교환을 한다.
물론 둘 다 교환할 필요가 없다면 갱신 과정은 종료되지만 해당 그림에선 6과 7 둘 다 현재 노드보다 크므로 왼쪽 노드인 7과 교환을 한 후 왼쪽 노드로 내려가겠다.
왼쪽으로 내려간 현재 노드와 자식 노드들을 비교했을 때 오른쪽 자식인 6이 더 크므로 오른쪽 자식과 교환을 한 후 내려갔지만 더 이상 자식 노드가 없으므로 여기서 갱신 과정은 종료된다.
갱신 과정을 보다 보면 알겠지만 항상 부모 노드와 자식 노드와의 관계에서 힙 특성을 유지하게끔 변경하는 과정이 일어나는 것을 알 수 있다.
이를 통해 갱신 과정은 범위가 절반씩 줄어드므로 O(logn)의 시간 복잡도가 걸리는 것을 알 수 있고 이진 탐색 트리(Binary Search Tree)와는 다르게 형제 노드끼리의 크기 차이는 신경 쓸 필요가 없다는 것도 확인할 수 있다.
구현
물론 이 힙의 삽입, 삭제 과정을 구현하는 것은 어렵진 않지만 고려할 요소들과 실수 가능성을 생각하면 시간제한이 있는 코딩 테스트에서 직접 구현하는 것은 상당히 비효율적이다.
다행히 다양한 이름으로 라이브러리가 있는데 파이썬에서는 heapq라는 모듈을 사용하면 된다.
따라서 해당 포스팅에서는 heapq의 사용방법을 익히도록 하겠다.
import heapq
data_list=[]
input_data=[5,9,3,1]
print("최소 힙 초기 원소 :",data_list)
for i in input_data:
print(i,"추가")
heapq.heappush(data_list,i)
print(data_list)
print("\n최소 힙 루트 노드의 원소 :",data_list[0],end="\n\n")
for i in range(len(input_data)):
print(heapq.heappop(data_list),"삭제")
print(data_list)
print("\n기존 input 리스트 :",input_data)
heapq.heapify(input_data)
print("Heapify 후 input 리스트 :",input_data)
print("\n최대 힙 초기 원소 :",data_list)
for i in input_data:
print(i,"추가")
heapq.heappush(data_list,(-i,i))
print(data_list)
print("\n최대 힙 루트 노드의 원소 :",data_list[0][1],end="\n\n")
for i in range(len(input_data)):
print(heapq.heappop(data_list)[1],"삭제")
print(data_list)
파이썬에서는 힙 구조를 만들 때 새로운 자료구조를 취급하는 게 아니라 기존의 리스트에 heapq란 모듈을 통해 힙의 특성을 가지며 heapq는 크게 3가지 함수가 있다.
원소를 넣는 heappush(), 원소를 삭제하는 heappop(), 리스트를 힙의 형태로 변환하는 heapify()다.
또한 heapq는 기본적으로 최소 힙의 특성을 가진다.
첫 번째 반복문을 통해 input_data의 원소를 하나씩 삽입하면서 최소 힙을 유지하는 것을 알 수 있다.
두 번째 반복문은 heappop()을 통해 루트 노드를 제거하면서도 최소 힙의 특성을 유지하는 것을 알 수 있다.
또한 18번째 줄을 통해 기존의 리스트를 힙의 형태로 변환하는 것도 확인할 수 있다.
3번째 반복문에서는 기본적으로 최소 힙의 특성을 갖는 heapq를 최대 힙으로 활용하기 위해서 튜플로 원소를 삽입한 것을 알 수 있다.
기존의 원소에 -1을 곱하여 음수로 만들고 해당 음수 값과 양수 값을 같이 넣으면 음수 값을 통해 최소 힙으로 정렬된다.
음수 값을 통해 최소 힙으로 정렬이 되므로 같이 들어간 양수 값은 자동적으로 최대 힙으로 정렬이 되는 원리를 이용한 것이고 튜플로 넣었기 때문에 pop() 할 때 인덱스 1로 접근한 것을 30번째 줄에서 확인할 수 있다.

모듈 import도 쉽고 함수도 어렵지 않아서 한 두 번 보면 쉽게 익힐 수 있을 것이다.
이를 코테에 활용하면 보다 쉽게 통과할 수 있을 것이다.
'알고리즘 > 자료구조 알고리즘 강의' 카테고리의 다른 글
| [PDF 전자책] 파이썬을 이용한 업무 자동화 프로그램 만들기 (0) | 2023.08.25 |
|---|---|
| [알고리즘] 이진 탐색 트리(Binary Search Tree) (Python) (0) | 2021.12.18 |
| [자료구조] 트리(Tree) 이진 트리(Binary Tree) 트리 순회 (Tree Traversal) (Python) (0) | 2021.12.09 |
| [자료구조] 스택(Stack)과 큐(Queue) 데크(Deque)까지 (Python) (0) | 2021.12.04 |
| [알고리즘] 이진탐색 / 이분탐색 (Binary Search) (Python) (0) | 2021.12.02 |