데이터 전처리를 위한 파이썬 Pandas 사용하기


데이터 분석을 하기 위해선 수집된 데이터(Raw Data)를 목적에 맞게끔 가공하는 작업이 필요하다.
순금을 뽑기 위해 불순물을 제거하는 것처럼 분석하고자 하는 목적에 맞는 데이터를 추출해야 보다 정확한 분석이 가능하기 때문이다.
Raw Data를 분석에 적합한 형태로 가공하는 작업을 전처리 작업이라고 하는데 이 전처리 작업에 유용한 라이브러리인 Pandas에 대해 데이터 분석과 시각화 관련된 공부를 하는 김에 정리하려고 한다.
Pandas란
Pandas는 데이터 조작과 분석을 위한 Python의 라이브러리이다.
데이터 구조는 Series와 DataFrame으로 구성되어 있다.
- 시리즈(Series): 시리즈는 1차원 배열과 같은 데이터 구조로, 각각의 데이터에 인덱스가 부여되어 있다.
예를 들어, 날씨 정보를 담은 시리즈에서는 날짜가 인덱스로 사용되고, 각 날짜에 해당하는 온도가 시리즈의 값으로 들어갈 수 있다. - 데이터프레임(DataFrame): 데이터프레임은 연속된 여러 시리즈로 엑셀과 같은 표 형식의 2차원 배열 데이터 구조다.
예를 들어, 여러 날짜에 대한 온도, 습도, 강수량 정보를 담은 여러 시리즈를 합쳐서 데이터프레임으로 만들 수 있다.
Pandas를 이용하여 Data를 쉽게 로딩하고 정리, 분석, 시각화할 수 있으며 DB와 유사한 연산을 지원하기 때문에 Data를 편리하게 처리할 수 있다.
따라서 Pandas는 데이터 분석, 머신러닝, 통계 등 다양한 분야에서 사용된다.
Pandas 사용하기
Pandas를 설치하는 명령어는 다음과 같다.
pip install pandas
위 사진처럼 뜬다면 설치가 완료된 것이다.
각 함수를 사용한 결과를 보면서 어떤 상황엔 어떤 함수를 써야 하는지 알아보자.
1. 데이터 읽어오기
크게 엑셀에서 읽어오거나 직접 데이터를 입력하는 두 가지 방법이 있다.
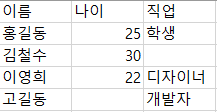
위 사진과 같은 데이터가 있을 때 Pandas에서 사용하는 코드와 출력 결과는 다음과 같다.
import pandas as pd
# 엑셀 파일에서 데이터 읽어오기
excel_file_path = 'user_data.xlsx'
# csv파일일 경우
# df = pd.read_csv(excel_file_path, encoding='utf-8-sig')
# excel파일일 경우
df = pd.read_excel(excel_file_path)
# 읽어온 데이터 출력
print(df)
# 직접 데이터 입력
data = {'이름': ['홍길동', '김철수', '이영희','고길동'],
'나이': [25, 30, 22, None],
'직업': ['학생', None, '디자이너','개발자']}
# 데이터프레임 생성
df = pd.DataFrame(data)
# 생성한 데이터프레임 출력
print(df)
# 데이터 일부 확인
print("df.head(2)")
print(df.head(2))
print("df.tail(1)")
print(df.tail(1))

출력 결과를 보면 알 수 있듯이 엑셀처럼 2차원 배열 형태를 확인할 수 있고 첫 번째 행이 컬럼 명, 두 번째 행부터는 자동으로 인덱스가 붙어있다.
직접 데이터를 넣을 경우엔 딕셔너리의 키를 컬럼 명으로, 값을 데이터 리스트로 만든 후 DataFrame 함수의 파라미터로 넣으면 된다.
또한 데이터가 많을 경우 전체 출력을 하기 어렵기 때문에 데이터 구조나 예시 데이터를 확인하기 위해 head(), tail() 함수를 사용하면 된다.
Default는 5줄이고 파라미터에 넣은 숫자만큼의 행을 가져오기 때문에 SQL의 LIMIT과 같은 기능이다.
print("컬럼 명")
print(df.columns)
print("행, 열 크기")
print(df.shape)
print("데이터 정보 확인")
print(df.info())
print("요약 통계 확인")
print(df.describe())
각각의 출력 결과는 다음과 같다.
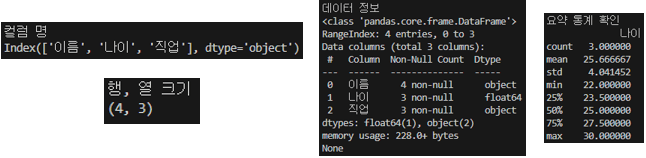
컬럼명과 행열의 크기, 데이터들의 대략적인 요약, 숫자 데이터들의 통계를 확인할 수 있다.
이를 이용해 행렬의 크기와 non-null의 Count를 비교해서 데이터가 없는(Null 값인) 부분이 있다면 차후에 계측값 제거를 통해 가공해야겠다는 생각을 할 수 있다.
Data Frame에서 특정 컬럼을 선택하여 Series를 추출할 수 있는데 컬럼 하나를 추출할 때와 여러 개를 추출할 때의 파라미터 값을 잘 확인해야 한다.
print("열 선택")
selected_column = df['나이']
print(selected_column.head())
print(selected_column.size, selected_column.count())
selected_columns = df[['이름', '나이']]
print(selected_columns.head())
print(selected_columns.size)
print(selected_columns.count())
print(selected_columns.value_counts())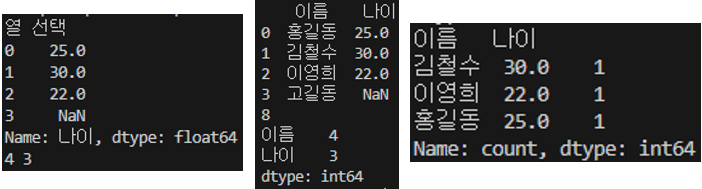
단일 컬럼 선택 시 문자열 하나만 들어가지만 복수 컬럼 선택 시 리스트 형태의 컬럼명을 파라미터로 보내며 Count 관련 함수는 Null 값이 들어간 행을 제외하고 세기 때문에 Law Data에서 자신에게 필요한 데이터만 추출하면 유용하게 사용할 수 있다.
print('조건식을 이용한 열 선택')
selected_column = df[df['이름'] == "홍길동"]
print(selected_column.head())
특히 특정 조건에 해당하는 데이터를 추출하려면 컬럼 선택 값으로 추출하고자 하는 조건식을 사용하면 된다.
이를 이용하면 특정 나이대, 특정 지역에 해당하는 데이터를 추출할 수 있다.
print("Null 값이 있는 데이터 갯수")
print(df.isnull().sum())
print("Null값을 제거한 데이터")
print(df.dropna())
print("직업의 Null값을 제거한 데이터")
print(df.dropna(subset=['직업']))
isnull() 함수는 데이터가 Null인 경우 True를 반환하는데 Sum()을 통해 합계를 구함으로써 Null값을 카운트하는 효과를 낼 수 있다.
또한 dropna()는 데이터가 Null인 행을 제거한 데이터를 반환하며 파라미터로 특정 컬럼의 Null 값만 제거할 수 있기 때문에 항상 Law Data를 다루기 전 dropna()를 사용하여 빈 값이 있으면 안 되는 컬럼의 데이터를 제거하는 게 좋을 것 같다.
print("Null값 채우기")
print(df.fillna({'나이' : 0 , '직업' : '없음'}))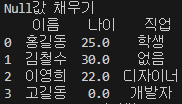
반대로 Null 값을 일괄적으로 채워야 할 때가 있는데 fillna() 함수를 사용하면 된다.
한 가지 값으로 채울 수 있다면 해당 값만 파라미터로 보내면 되지만 컬럼마다 초기화해야 하는 값이 다르다면 딕셔너리 형태로 Key는 컬럼명, Value는 Data 값으로 설정하면 위 사진처럼 채워진다.
'취업 후 학습' 카테고리의 다른 글
| MSSQL 테이블 변수, 임시 테이블 사용하기 (0) | 2023.12.04 |
|---|---|
| 스프링 Annotation(어노테이션) 정리 (0) | 2023.06.28 |
| 스프링이란? 스프링과 스프링 부트의 차이점은? (0) | 2023.06.20 |
| 리액트 data.map is not a function 에러 해결 (0) | 2023.05.03 |
| 파이썬 Pyautogui로 매크로 만들기 (0) | 2023.02.26 |