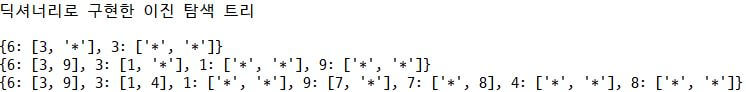DP란 정해진 방식이 있는 게 아니라 큰 문제를 해결하기 위해 문제를 세분화시키고 각각 작은 문제를 해결하여 나온 값들을 이용하는 방식을 총체적으로 지칭하는 알고리즘이다.
따라서 이미 연산한 값을 이용함으로써 불필요한 연산을 줄일 수 있다.
이것의 대표적인 예시가 피보나치 수열이다.
매번 필요한 값을 연산하도록 구현할 수 있지만 DP를 활용하게 되면 획기적으로 연산 횟수가 줄어들기 때문에 더 많은 수열을 구할 수 있다.
다시 문제로 돌아와서 문제는 A란 수열에서 원소가 증가하는 부분 수열을 찾는 것이며 각 원소는 연속하지 않아도 된다.
해당 문제는 최장 증가 수열(Least Increasing Subsequence) 알고리즘으로 알려져 있으며 DP를 활용하는 기법이기도 하다.
문제의 조건은 다음과 같다.
수열 A의 크기는 1000 이하다.
각 원소도 1000 이하의 자연수이다.
수열 A의 크기는 1000 이하이므로 O(n^2)의 시간 복잡도도 충분히 연산이 가능하다.
바로 전체 코드를 통해 어떻게 DP를 활용했는지 확인해 보자.
n=int(input())
sequence=list(map(int,input().split()))
res=[0 for i in range(n)]
res[0]=1
for i in range(1,n):
cnt=0
for j in range(0,i):
if sequence[j]<sequence[i] and cnt<res[j]:
cnt=res[j]
res[i]=cnt+1
print(max(res))
3번째 줄 res란 리스트가 DP를 활용하는 리스트이기 때문에 핵심 포인트이다.
sequence는 원래의 수열 A를 뜻하고 res는 각 원소가 부분 수열의 몇 번째에 해당하는지를 나타낸다.
따라서 n만큼 수열의 길이를 입력받으므로 res를 n의 길이만큼 초기화시키고 res의 0번째 인덱스를 1로 한 이유는 0번째 인덱스의 원소가 부분 수열의 첫 번째 원소가 된다는 의미이다.
5번째 줄부터 중첩 for문을 사용하는데 버블 정렬과 원리는 비슷하다.
첫 번째 for문에서는 1번째 원소부터 n-1번째 원소까지 반복하는데 매번 카운트를 0으로 초기화하고 두 번째 for문에서는 i번째 원소보다 작으면서 카운트보다 res의 원소가 더 크다면 카운트를 갱신한다.
즉 해당 원소보다 작은 원소들이 최대한 몇 개 포함될 수 있는지 계산하는 방식이다.
두 번째 for문이 끝나면 res의 i번째를 카운트+1로 갱신한다.
예를 들어 카운트가 2라면 i번째 인덱스는 3이 되고 i번째 원소보다 작은 원소가 두 개, i번째 원소는 부분 수열의 3번째 원소가 될 수 있다는 의미이다.
이렇게 리스트에 몇 번째 원소가 될 수 있는지 카운트함으로써 부분 수열을 일일이 구하지 않아도 최장 길이를 구할 수 있다.
투 포인터 알고리즘이란 두 개의 지점을 이동시키면서 연속된 숫자의 합(구간 합)을 구하는 알고리즘이다.
비슷한 알고리즘으로 슬라이딩 윈도우(Sliding Window)가 있는데 이 둘의 차이점은 구간의 길이다.
슬라이딩 윈도우는 구간의 길이가 정해져 있고, 투 포인터는 상황에 따라 변한다.
또한 투 포인터는 음수가 존재할 경우 구간의 길이가 증가했을 때 구간 합이 증가할지 감소할지 보장할 수 없으므로양의 정수만 존재할 때 사용 가능하다는 특징이 있다.
그림을 통해 이해하면 쉬울 것이다.
다음과 같이 자연수로 이루어진 리스트가 있을 때 합이 5인 구간의 최소 길이를 찾는 예시를 보자.
이때 두 가지 변수를 Left, Right로 선언하고 처음부터 Right 변수를 오른쪽으로 움직이며 구간 합에 원소를 합하고 Left 변수를 오른쪽으로 움직이며 구간합에 원소를 빼는 방식이다.
먼저 Right 변수가 첫 번째 원소를 가리킬 때다.
Sum에 해당하는 원소를 더하고 5와 비교했을 때 더 작으므로 구간을 늘려야 한다.
따라서 Right 변수를 옮겨야 한다.
Right 변수를 옮기고 나서 구간합이 5가 되므로 이 구간의 길이를 갱신시키면 된다.
최소 길이를 구해야 하므로 Left 변수를 옮기면 된다.
Left 변수를 옮기고 나서 Sum이 5보다 작으므로 Right 변수를 옮긴다.
Right 변수를 옮긴 뒤 Sum이 5보다 크므로 Left 변수를 옮겨 구간 합을 더 작게 만든다.
Left 변수를 옮기고 Sum이 5보다 더 크지만 동일한 원소(구간의 길이가 1)를 가리키므로 Right 변수를 옮긴다.
Right 변수를 옮긴 뒤 Sum이 5보다 크므로 Left 변수를 옮긴다.
Left 변수를 옮긴 뒤 해당 원소를 빼주니 Sum이 5이다.
해당 구간의 길이는 1이므로 구간 길이를 갱신해주고 Right 변수를 옮긴다.
Right 변수를 옮기니 리스트를 벗어나므로 탐색을 종료한다.
인덱싱을 어떻게 구현하는지는 본인의 자유이며 인덱싱 과정이 헷갈릴 수 있기에 여러 가지 방법 중에 가장 자신한테 적합한 방식을 적용하는 편이 좋을 것 같다.
다음은 문제를 푼 전체 코드이다.
n,s=map(int,input().split())
left=-1
right=0
min_len=100001
num_array=list(map(int,input().split()))
temp_sum=num_array[0]
while right<n:
if temp_sum>=s:
if min_len>right-left:
min_len=right-left
left+=1
temp_sum-=num_array[left]
else:
right+=1
if right<n:
temp_sum+=num_array[right]
if min_len==100001:
print(0)
else:
print(min_len)
문제에서 수열의 길이 N은 100000 미만이므로 100000 이상의 숫자 중 아무거나 구간의 최소 길이로 정하고 그걸 갱신하면 최소 길이를 구할 수 있다.
만약 처음에 정한 숫자가 그대로 있다면 합이 s보다 큰 구간이 없단 뜻이며 4번째 줄에선 선언하고, 17번째 줄에선 판단하도록 구현했다.
7번째 줄의 while문에서는 right 변수가 수열의 길이를 넘어가면 안 되므로 길이(n) 미만일 때까지만 반복을 한다.
또한 while문 내부에서는 구간합이 S이상이면 길이를 갱신하고 Left를 이동시켜 원소를 구간합에서 빼고 구간합이 S미만이면 Right를 이동시켜 원소를 구간합에 더하도록 구현했다.
결과 화면
인덱싱 과정이 다소 헷갈릴 수 있는 알고리즘이라서 소수의 원소를 집어넣고 접근하는 과정을 하나씩 출력하다 보면 실수를 줄일 수 있을 것이다.
이진 트리와 순회에 대해 구현한 경험이 있다면 아주 쉽게 풀 수 있는 문제지만 경험이 없다면 아마 상당히 막막하게 느껴질 수 있는 문제라고 생각한다.
다행히 파이썬은 딕셔너리란 자료구조를 지원하므로 딕셔너리를 이용해서 아주 쉽게 구현해보겠다.
def preorder(trees,root):
print(root,end="")
if trees[root][0]!=".":
preorder(trees,trees[root][0])
if trees[root][1]!=".":
preorder(trees,trees[root][1])
def inorder(trees,root):
if trees[root][0]!=".":
inorder(trees,trees[root][0])
print(root,end="")
if trees[root][1]!=".":
inorder(trees,trees[root][1])
def postorder(trees,root):
if trees[root][0]!=".":
postorder(trees,trees[root][0])
if trees[root][1]!=".":
postorder(trees,trees[root][1])
print(root,end="")
n=int(input())
trees={}
root="A"
for i in range(n):
temp=input().split()
trees[temp[0]]=[temp[1],temp[2]]
preorder(trees,root)
print()
inorder(trees,root)
print()
postorder(trees,root)
문제를 간략하게 다시 설명하자면 0은 비어있는 땅, 1은 배추가 있는 땅이고 각 케이스마다 배추가 이어져있는 구역을 세서 출력하면 된다.
그래프를 탐색하는 방법은 스택을 쓰는지, 큐를 쓰는지에 따라 깊이 우선 탐색(DFS), 너비 우선 탐색(BFS)으로 나뉘는데 둘 다 시간 복잡도는 비슷하므로 편한 방식으로 구현하면 된다.
필자는 최단 거리를 찾을 때 BFS가 유리하므로 보통 BFS로 구현한다.
바로 전체 코드를 확인해 보자.
testcase=int(input())
dir=[[-1,0],[0,1],[1,0],[0,-1]]
for i in range(testcase):
queue=[]
res=0
M,N,K=map(int,input().split())
graph=[[0 for j in range(M)]for k in range(N)]
for j in range(K):
tempm,tempn=map(int,input().split())
graph[tempn][tempm]=1
for j in range(N):
for k in range(M):
if graph[j][k]==1:
res+=1
queue.append([j,k])
graph[j][k]=0
while len(queue)>0:
tempn,tempm=queue.pop(0)
for a in range(len(dir)):
dx=tempn+dir[a][0]
dy=tempm+dir[a][1]
if 0<=dx<N and 0<=dy<M and graph[dx][dy]==1:
graph[dx][dy]=0
queue.append([dx,dy])
print(res)
1번째 줄은 테스트 케이스만큼 반복하기 위한 변수이고 2번째 줄은 각 노드에서 탐색 방향(위, 오른쪽, 아래, 왼쪽)을 묶어놓은 리스트이다.
이렇게 방향을 리스트로 묶으면 4가지 방향을 탐색할 때 반복문으로 해결할 수 있다는 장점이 있기에 꼭 잊지 말길 바란다.
대부분은 4가지 방향이지만 가끔 대각선도 고려하는 8가지 방향 문제도 있는데 단순하게 방향을 고려해서 8개의 리스트를 넣으면 된다.
4번째 줄의 queue는 큐를 사용함으로써 BFS 방식을 쓰기 위해 선언한 리스트이다.
가끔 리스트를 큐 방식으로 쓸 때 시간 초과가 나는 경우가 있는데 이는 pop() 함수에서 마지막 원소부터 탐색하기 때문에 첫 번째 원소를 제거하기 위해서는 O(n)의 시간 복잡도가 걸리기 때문이다.
그럴 경우엔 deque 모듈을 사용하면 O(1)로 첫 번째 원소에 삽입하고 삭제할 수 있다.
8번째 줄은 배추의 위치를 갱신하는 반복문이고 11번째 줄부터는 그래프를 전체 탐색하면서 배추 구역을 카운트하는 반복문이다.
13번째 줄은 배추가 있을 경우 카운트를 하고 인접한 배추 구역을 0으로 바꾸는 작업이다.
보통 원본 그래프를 변경하지 않기 위해 visited로 그래프와 똑같은 크기의 리스트를 선언하고 방문한 노드인지 아닌지 체크하여 중복된 방문을 방지하는데 해당 문제에서는 단지 배추 구역만 세면 되므로 원본 리스트를 변경해도 상관없어서 아예 0으로 바꿨다.
또한 20, 21번째 줄에서 탐색할 노드의 위치를 계산하여 따로 변수에 저장하는 이유는 미리 값을 저장해놔야 그래프 크기 안인지 배추가 있는 노드인지 체크할 때 불필요한 연산 횟수를 줄일 수 있기 때문에 값을 저장하는 것을 추천한다.
결과 화면
탐색 방향을 고려할 필요도 없고 단지 구역만 세면 되기 때문에 그래프 문제 중에서도 꽤 쉬운 편에 속한다고 생각한다.
이진 탐색 트리(Binary Search Tree)란 왼쪽 서브 트리는 자신보다 작은 수들만 존재하고 오른쪽 서브 트리는 자신보다 큰 수들만 존재하는 이진트리를 뜻한다.
단순한 이진트리는 원하는 값의 존재 여부를 확인하려면 트리 전체를 탐색해야 한다.
따라서 자료구조로써의 효율이 떨어진다.
그래서 나온 것이 이진 탐색 트리이며 왼쪽은 작은 수, 오른쪽은 큰 수를 유지함으로써 탐색하는데 O(logn)의 효율적인 시간 복잡도를 가질 수 있다.
또한 모든 원소들은 서로 다른 값을 가진다는 조건이 붙어있다.
삽입과 삭제 과정을 그림을 통해 보면 이해가 쉬울 것이다.
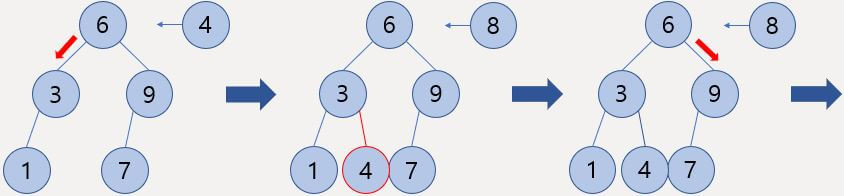
이진 탐색 트리의 삽입 연산
먼저 트리는 항상 루트부터 시작한다.
기존의 트리에서 4를 추가하기 위해 루트 원소를 살펴보니 6으로 4가 더 작기 때문에 왼쪽 자식 노드로 내려간다.
다시 비교해보니 추가하려는 원소가 더 크기 때문에 오른쪽으로 내려가야 되는데 더 이상 자식 노드가 없으므로 오른쪽 자식 노드로 추가한다.
그다음 8을 추가하기 위해 다시 루트 노드부터 탐색을 시작한다.
6보다 크니 오른쪽 자식 노드로 내려가고 9보다 작으니 왼쪽 자식 노드, 7보다 크니 오른쪽 자식 노드로 내려가는데 이때 오른쪽 자식 노드가 없으므로 오른쪽에 노드를 추가하면 된다.
루트에서 시작해서 매번 범위를 절반씩 줄여 나가므로 삽입 시 O(logn)의 시간 복잡도가 걸린다.
삽입 연산이 크기 비교만을 통해 탐색 후 추가하는 거라 상당히 단순하기 때문에 삽입에 비해서 삭제 연산은 다소 복잡하게 느껴질 수 있다.
하지만 케이스를 나눠 순서를 따라가면 이해할 수 있을 것이다.
케이스는 크게 2가지로 삭제할 노드가 단말 노드인 경우, 자식 노드가 존재하는 경우로 나눠서 생각하면 된다.
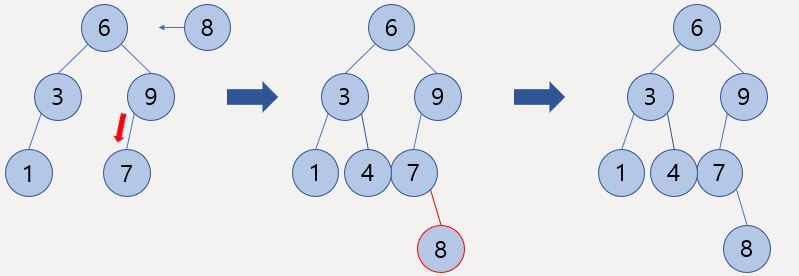
단말 노드일 때 삭제 연산
삭제 노드를 찾기 위한 탐색은 삽입 연산과 동일하다.
먼저 가장 간단한 경우인 삭제할 노드가 단말 노드인 경우는 그냥 해당 노드와 부모 노드의 관계를 끊어주고 삭제하면 된다.
자식 노드가 존재할 경우 삭제 연산
두 번째는 자식 노드가 존재할 경우이다.
통상 이진 탐색 트리의 삭제는 단말 노드인 경우, 자식 노드가 한 개인 경우, 자식 노드가 두 개인 경우 이렇게 나누는데 자식 노드가 하나나 둘이어도 원리는 같은 방식이니 굳이 구분 짓진 않겠다.
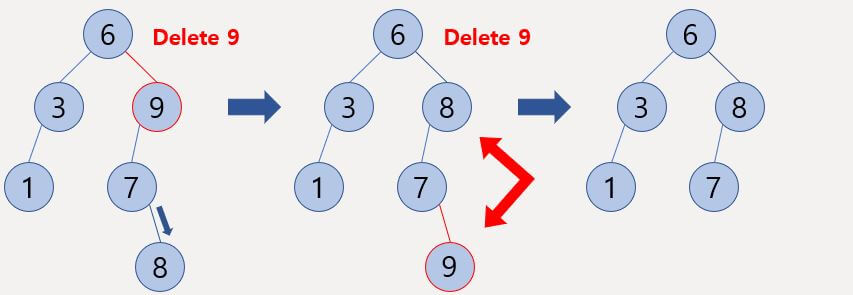
기억해야 할 중요한 점은 삭제할 노드와 가장 차이가 적게 차이나는 노드로 교체한다는 것이다.
이것과 이진 탐색 트리의 특성을 기억한다면 방식을 까먹을 일은 없다.
즉, 삭제할 노드의 왼쪽 자식(왼쪽 서브 트리)으로 내려갔다면 가장 차이가 적게 나는 값을 찾기 위해 최대한 오른쪽 자식 노드(오른쪽 서브 트리)로 이동해야 값을 찾을 수 있을 것이고, 반대로 오른쪽 자식 노드로 내려갔다면 가장 차이가 적게 나는 값을 찾기 위해 최대한 왼쪽 자식 노드로 이동해야 값을 찾을 수 있을 것이다.
가장 차이가 적게 나는 노드를 찾았다면 원래 삭제할 노드와 값을 교환하고 단말 노드의 삭제를 하면 된다.
그림을 보면 삭제할 9를 찾기 위해 루트 노드의 오른쪽 자식으로 이동하여 삭제할 노드를 찾았고, 왼쪽 자식이 있으므로 왼쪽으로 이동 후 오른쪽 자식 노드가 존재하지 않을 때까지 오른쪽 자식 노드로 이동하였다.
결국 8을 찾았고 이를 9와 교체한 뒤 삭제하면 된다.
전체적으로 보면 알겠지만 삽입과 삭제 과정에서도 꾸준히 이진 탐색 트리의 특성을 유지하는 것을 알 수 있다.
구현
이진 트리를 구현하는 3가지 방법을 소개하겠다.
리스트(배열)로 구현
딕셔너리로 구현
구조체로 구현
보통 리스트로 구현하는 방법은 낭비되는 공간이 많으므로(공간 복잡도가 비효율적이므로) 구조체로 구현하는 방법을 많이 쓴다.
또한 파이썬은 키, 값을 갖는 딕셔너리로도 구현이 가능하기 때문에 상황에 맞게 자신이 편한 방식대로 구현하면 된다. (필자는 딕셔너리가 가장 편하고 쉬우며 효율적이기에 자주 쓴다.)
코딩 테스트를 기준으로 보통 이진 탐색 트리가 나온다면 삽입이나 순회가 나온다.
삭제를 실제로 구현하기엔 다소 복잡하기 때문이다.
따라서 이진 탐색 트리를 다양하게 구현해보고 노드 삽입까지 해보겠다.
def list_insert(curr,num):
if binary_tree[curr]=='*':
binary_tree[curr]=num
elif num<binary_tree[curr]:
list_insert(2*curr,num)
else:
list_insert(2*curr+1,num)
print("리스트로 구현한 이진 탐색 트리\n")
binary_tree=['*' for i in range(16)]
root=1
list_insert(root,6)
list_insert(root,3)
print(binary_tree)
list_insert(root,1)
list_insert(root,9)
print(binary_tree)
list_insert(root,7)
list_insert(root,4)
list_insert(root,8)
print(binary_tree)
리스트로 구현할 때는 연산의 편의성 때문에 인덱스 1을 루트 노드로 가정한다.
인덱스 1을 루트로 하기 때문에 인덱스*2는 왼쪽 자식 노드, 인덱스*2+1은 오른쪽 자식 노드로 생각할 수 있다.
트리의 형태는 본문의 노드 삽입 결과와 똑같기 때문에 결과 화면과 그림을 비교해보면서 인덱스를 추적하면 이해가 될 것이다.
리스트 결과 화면
def dic_insert(curr,num):
global root
if len(binary_tree)==0:
root=num
binary_tree[root]=['*','*']
else:
if num<curr:
if binary_tree[curr][0]=='*':
binary_tree[curr][0]=num
binary_tree[num]=['*','*']
else:
dic_insert(binary_tree[curr][0],num)
else:
if binary_tree[curr][1]=='*':
binary_tree[curr][1]=num
binary_tree[num]=['*','*']
else:
dic_insert(binary_tree[curr][1],num)
print("딕셔너리로 구현한 이진 탐색 트리\n")
binary_tree={}
root=None
dic_insert(root,6)
dic_insert(root,3)
print(binary_tree)
dic_insert(root,1)
dic_insert(root,9)
print(binary_tree)
dic_insert(root,7)
dic_insert(root,4)
dic_insert(root,8)
print(binary_tree)
딕셔너리는 키를 노드의 원소, 값을 길이가 2인 리스트로 선언하여 왼쪽 자식과 오른쪽 자식으로 구분 짓는다.
따라서 딕셔너리의 길이가 0일 땐 루트의 원소로 갱신하고 새로운 노드를 삽입할 땐 부모 노드에서 자식 노드를 갱신하고 초기화된 노드를 추가하는 것을 잊지 말아야 한다.
딕셔너리 결과 화면
class Node:
def __init__(self,num):
self.data=num
self.left=self.right=None
class Binary_tree:
def __init__(self):
self.root=None
def Node_insert(self,num):
if self.root==None:
self.root=Node(num)
else:
self.curr=self.root
while True:
if num<self.curr.data:
if self.curr.left==None:
self.curr.left=Node(num)
break
else:
self.curr=self.curr.left
else:
if self.curr.right==None:
self.curr.right=Node(num)
break
else:
self.curr=self.curr.right
print("구조체로 구현한 이진 탐색 트리\n")
Binary=Binary_tree()
Binary.Node_insert(6)
Binary.Node_insert(3)
Binary.Node_insert(1)
Binary.Node_insert(9)
Binary.Node_insert(7)
Binary.Node_insert(4)
Binary.Node_insert(8)
구조체로 구현하는 방식은 노드에 대한 구조체를 선언하고 해당 노드들을 이진 트리의 구조체로 묶는 형식이다.
파이썬의 특성상 Class의 인스턴스를 생성한 뒤 첫 번째 인자로 넘기기 때문에 self로 받는다.
이런 부분까지 다루게 되면 상당히 복잡하고 어려워지므로 이진 탐색 트리는 여기까지 하도록 하겠다.
처음 생각한 풀이법은 노드의 수는 10,000개 이하고 전위 순회의 결과가 입력으로 주어지니 전위 순회 순서대로 트리에 삽입하여 완성된 트리를 후위 순회하여 출력하는 방식을 생각했었다.
하지만 생각치 못하게 시간 초과와 메모리 초과가 떠서 틀렸었다.
불합격 이미지
다음은 불합격한 코드이다.
import sys
sys.setrecursionlimit(10**6)
binary_tree={} #이진 트리를 위한 딕셔너리 선언
while True:
try:
num=int(input())
if len(binary_tree)==0: #빈 트리일 때
root=num #루트로 설정
binary_tree[root]=['*','*']
else:
curr=root
while True:
#왼쪽 서브 트리일 때
if num<curr:
#왼쪽 노드가 없을 때
if binary_tree[curr][0]=='*':
binary_tree[curr][0]=num
binary_tree[num]=['*','*']
break
#왼쪽 자식 노드로 이동
else:
curr=binary_tree[curr][0]
#오른쪽 서브 트리일 때
else:
#오른쪽 노드가 없을 때
if binary_tree[curr][1]=='*':
binary_tree[curr][1]=num
binary_tree[num]=['*','*']
break
#오른쪽 자식 노드로 이동
else:
curr=binary_tree[curr][1]
except:
break
def postorder(curr):
#왼쪽 자식 노드로 이동
if binary_tree[curr][0]!='*':
postorder(binary_tree[curr][0])
#오른쪽 자식 노드로 이동
if binary_tree[curr][1]!='*':
postorder(binary_tree[curr][1])
#현재 노드 출력
print(curr)
postorder(root)
2번째 줄은 파이썬에서 기본 재귀 깊이 제한이 1000이기 때문에 1000000으로 세팅하는 코드이다.
이 때문에 런타임 에러(Recursion Error)가 뜬 것이다.
또한 입력받는 부분에서 어디까지 받는다는 제한이 없으므로 try except 구문을 사용하여 예외가 발생하기 전까지 입력을 받고 트리에 추가하는 방식으로 하였다.
예외가 발생하면 그대로 트리를 후위 순회하여 출력했는데 불합격한 것을 보니 다른 방식을 생각해야 했다.
고민하던 중에 전위 순회는 현재 노드 -> 왼쪽 자식 노드 -> 오른쪽 자식 노드 순으로 탐색하고 후위 순회는 왼쪽 자식 노드 -> 오른쪽 자식 노드 -> 현재 노드 순으로 탐색하기 때문에 현재 노드를 출력하는 타이밍을 조절해야겠다는 생각이 들었고 현재 노드보다 작은 숫자는 왼쪽 서브 트리, 큰 숫자는 오른쪽 서브 트리로 구분 지을 수 있겠다는 생각이 들었다.
따라서 리스트를 기준으로 첫 번째 원소는 현재 노드라 마지막에 출력하고 현재 노드보다 작은 원소들의 리스트는 왼쪽 서브 트리로 여겨 재귀 호출, 큰 원소들의 리스트는 오른쪽 서브 트리로 여겨 재귀 호출하면 차례대로 왼쪽 서브 트리 -> 오른쪽 서브 트리 -> 현재 노드 순으로 출력될 것이라 생각했고 역시 통과했다.
다음은 통과한 전체 코드이다.
import sys
sys.setrecursionlimit(10**6)
#입력받을 원소 리스트
num_list=[]
while True:
try:
num=int(input())
num_list.append(num)
except:
break
def postorder(left,right):
#순서 역전시 종료
if left>right:
return
else:
mid=right+1 #분할 기준
for i in range(left+1,right+1):
#해당 원소가 현재 노드보다 크다면 그 전까지는 왼쪽 서브 트리,
#해당 원소 이후는 오른쪽 서브 트리이다.
if num_list[left]<num_list[i]:
mid=i
break
postorder(left+1,mid-1)
postorder(mid,right)
print(num_list[left])
postorder(0,len(num_list)-1)
트리 생성이 아닌 단순히 리스트에 원소를 입력 받으므로 입력 받는 부분은 전보다 더 간단해졌다.
시작은 전체 리스트의 길이부터 시작하고 가장 첫 번째 원소는 현재 노드, 그 이후부터 반복문을 돌면서 현재 노드보다 큰 원소가 있다면 그 전까지는 왼쪽 서브 트리, 큰 원소부터 이후는 오른쪽 서브 트리로 구분지어 재귀호출한다.
만약 큰 원소가 없을 경우를 대비해 mid=right+1을 함으로써 없으면 현재 노드를 제외한 나머지를 왼쪽 서브 트리로 보내고 두 번째 호출하는 재귀 함수는 순서가 역전되어 종료되도록 구현하였다.
결과 화면
인덱스를 접근하고 관리하는 방법에서 다소 헷갈리는 부분이 있고 알고리즘 외적으로도 재귀 깊이를 변경한다든지 입력받는데 처리해줘야 하는 부분이 있는 문제였다.
또한 해당 코드를 PyPy3로 제출하면 메모리 초과가 뜬다.
PyPy3가 Python3보다 연산이 빠르기에 안전하게 하기 위해 PyPy3로 먼저 제출했었는데 자료를 찾아보니 PyPy3는 최대 재귀 깊이는 제한이 없으나 10만 단위 이상으로 들어가면 Stack Overflow가 발생하여 재귀에 약하다는 정보를 얻을 수 있었다.
따라서 시간 초과가 뜬다면 PyPy3로, 재귀를 사용하여 메모리 초과가 뜬다면 Python3으로 제출해야한다는 지식을 알게 되었다.
문제를 좀 더 쉽게 설명하자면 길이가 N개인 수열이 있는데 여기서 두 개를 뽑아 서로 곱한 값을 모든 경우의 수에서 다 더한 뒤 1000000007로 나눈 값을 출력하라는 뜻이다.
즉, 수학의 조합(Combination)을 떠올리면 된다.
하지만 제한 조건을 잘 봐야한다.
수열의 길이는 최대 500000(50만)이 될 수 있으며 평소 조합을 구하는 방식대로 첫 번째 원소부터 완전 탐색, 두 번째 원소부터 완전 탐색 ... 이렇게 반복하면 O(n^2)의 시간 복잡도가 걸리므로 시간 초과가 날 수밖에 없다.
따라서 어떻게 해야되나 고민을 해본 결과 예제에서 힌트를 얻을 수 있었다.
예제는 '1 x 2 + 2 x 3 + 1 x 3 = 11' 이렇게 있었다.
이걸 원래 조합 구하는 방식으로 순서를 조금 바꿔보면 '1 x 2 + 1 x 3 +2 x 3 = 11' 이렇게 나타낼 수 있고 조금만 더 이해하기 쉽게 바꾸면 '1 x (2 + 3) +2 x 3= 11' 이렇게 나타낼 수 있다.
즉 문제가 원하는 답은 각 원소와 해당 원소의 뒷 원소들의 합을 곱하고이를 다 더한 값에 1000000007로 나눈 결과를 원하는 것이었다.
이렇게 하면 처음 수열의 합을 구할때 O(n), 수열 탐색할 때 O(n), 총 O(n)의 시간 복잡도가 걸리므로 시간 초과가 나지 않을 것이다.
다음은 전체 코드다.
n=int(input())
num_list=list(map(int,input().split()))
sum_list=sum(num_list)
res=0
for i in num_list:
sum_list-=i
res=(res+i*sum_list)%1000000007
print(res)
원리만 떠올린다면 구현 자체는 아주 쉬운 문제였다.
3번째 줄에서 sum() 함수는 O(n)의 시간 복잡도가 걸린다.
5번째 줄의 반복문에서는 해당 원소를 리스트의 합에서 빼주고 해당 원소와 리스트의 합을 곱한 값을 결과값(res)에 더하면서 1000000007의 나머지로 갱신하면 끝이다.
지문에서 N번째 숫자를 묻고 N은 1,000,000(백만) 이하의 자연수 혹은 0이므로 상당히 큰 숫자들을 비교해야 할 것 같지만 정작 주의해야 할 조건은 딱 하나다.
앞 자릿수부터 뒤로 갈수록숫자가 작아져야 한다.
예시에 나온 322처럼 같은 숫자가 연속해서 등장해도 감소하는 수가 아니므로 생각 가능한 최대 숫자는 9876543210이다.
물론 이 숫자 또한 90억이 넘는 숫자이므로 0부터 9876543210까지 차례대로(선형적으로) 감소하는 숫자인지 판단하려면 엄청난 연산 횟수가 나올 수밖에 없다.
하지만 이 숫자들을 자릿수를 기준으로 비교한다면 얘기가 달라진다.
즉, 1자리 수부터 10자리 수까지 앞자리보다 작은 숫자들만 이어 붙여준다면 불필요한 연산을 획기적으로 줄일 수 있다.
이 과정에서 백 트래킹을 재귀로 구현하며 무한 루프에 빠지지 않도록 탈출 조건을 잊지 않도록 한다.
아이디어만 떠올린다면 구현 자체는 어렵지 않은 문제이므로 전체 코드를 보면서 설명하겠다.
def add_digit(digit,num): #자리수에 따라 증가
if digit==1:
decreasing.append(num)
else:
for i in range(num%10):
add_digit(digit-1,num*10+i)
def backtracking(digit): #백트래킹 시작
for i in range(digit-1,10):
add_digit(digit,i)
decreasing=[] #감소하는 숫자 리스트
for i in range(1,11):
backtracking(i)
n=int(input())
if n>=len(decreasing): #감소하는 숫자가 없을 때
print(-1)
else:
print(decreasing[n])
크게 구성을 함수 두 개, 메인으로 나누었다.
물론 메인에서 중첩 for문을 통해 1자리 수부터 10자리 수까지 가능한 숫자들을 매개변수로 보낸다면 하나의 함수만 써도 되지만 직관적인 이해를 돕기 위해 기능을 분리하여 함수 두 개로 구현하였다.
첫 번째 함수 add_digit은 특정 자릿수까지 감소하는 숫자를 이어 붙이는 함수고 두 번째 함수 backtracking은 1 자릿수부터 10 자릿수까지 백 트래킹을 반복하는 함수다.
함수의 특성상 먼저 선언되어있어야 호출 가능하므로 조금 복잡하지만 함수의 흐름대로 설명하겠다.
먼저 12번째 줄에 decreasing으로 감소하는 숫자들을 넣을 리스트를 선언했다.
그리고 13번째 줄은 자릿수를 매개변수로 백 트래킹을 시작하기 위한 반복문이고 이해가 쉽도록 1부터 10까지 반복한다.
즉 1 자릿수부터 10자리 수까지 찾겠다는 의미이다.
그럼 8번째 줄인 backtracking 함수로 넘어가는데 이미 받은 digit변수와 같이 0부터 9까지 숫자를 파라미터로 넘긴다.
이 0부터 9는 실제 감소하는 수가 될 숫자들이다.
그렇게 add_digit으로 넘어가면 digit이 1자리일 때는 더 이상 추가할 숫자가 없으므로 decreasing 리스트에 숫자를 넣고 함수가 자동 종료된다.
만약 digit이 2 이상일 땐 뒷자리에 숫자를 추가해야 하므로 반복문을 통해 digit을 감소시킨 후 재귀 호출한다.
이때 추가해야 할 숫자가 바로 앞자리 숫자보다 작아야 하므로 num%10을 통해 바로 앞자리 숫자를 구하고 해당 숫자 미만까지만 반복문을 돌린다.
물론 2자리 수 이상부터는 첫자리에 0이 올 수 없지만 num%10은 0이라 for문을 수행하지 않아서 고려하지 않아도 된다.
또한 뒷자리에 숫자를 이어 붙이므로 원래 숫자인 num에 10을 곱해서 자릿수를 늘린 후 i를 더하면 원하는 숫자가 된다.
위의 재귀가 끝나면 decreasing 리스트에는 0부터 9876543210까지 감소하는 수가 들어가게 되고 N을 입력받아서 리스트의 인덱스를 벗어나면 불가능한 수이므로 -1을 출력, 벗어나지 않으면 해당 인덱스의 숫자를 출력하면 통과한다.
결과 화면
아무래도 이 문제가 골드로 측정된 것은 숫자를 자릿수로 비교하는 생각의 전환, 백 트래킹 적용 때문인 것 같다.
비교적 코드도 짧고 구현도 쉬운 편이기 때문이다.
아마 다양한 문제를 접하다 보면 이 정도 아이디어와 구현은 쉽게 떠올리고 구현할 수 있을 것이다.